数据库原理复习(考前救急专用)
Chapter 1 数据库系统引论
简介
主要参考的是王能斌老师编写的《数据库系统教程》第二版上册,每个标题旁边是对应书上的页码。
可恶啊,这学期数据库没怎么听课,还有三天就期末考了,我能补回来吗?
数据库基本概念 P2-5
数据库:A very large, integrated collection of data.
DBMS:A software package designed to store and manage databases.
- 文件系统 vs 数据库
- 应用程序需要在主存和外存中存储大量数据
- 对不同的查询有专属的代码
- 确保数据不会因为多并发用户而产生不一致性
- 对于崩溃的恢复
- 安全和访问的控制
数据库系统特点:P6-7
数据库三级模式与两级数据独立性 P 7-9
数据(Data):对事物描述的符号记录
数据模型(Data Model):用来描述数据的一组概念和定义
数据模式(Data Schema):对某一类数据的结构、联系和约束的描述
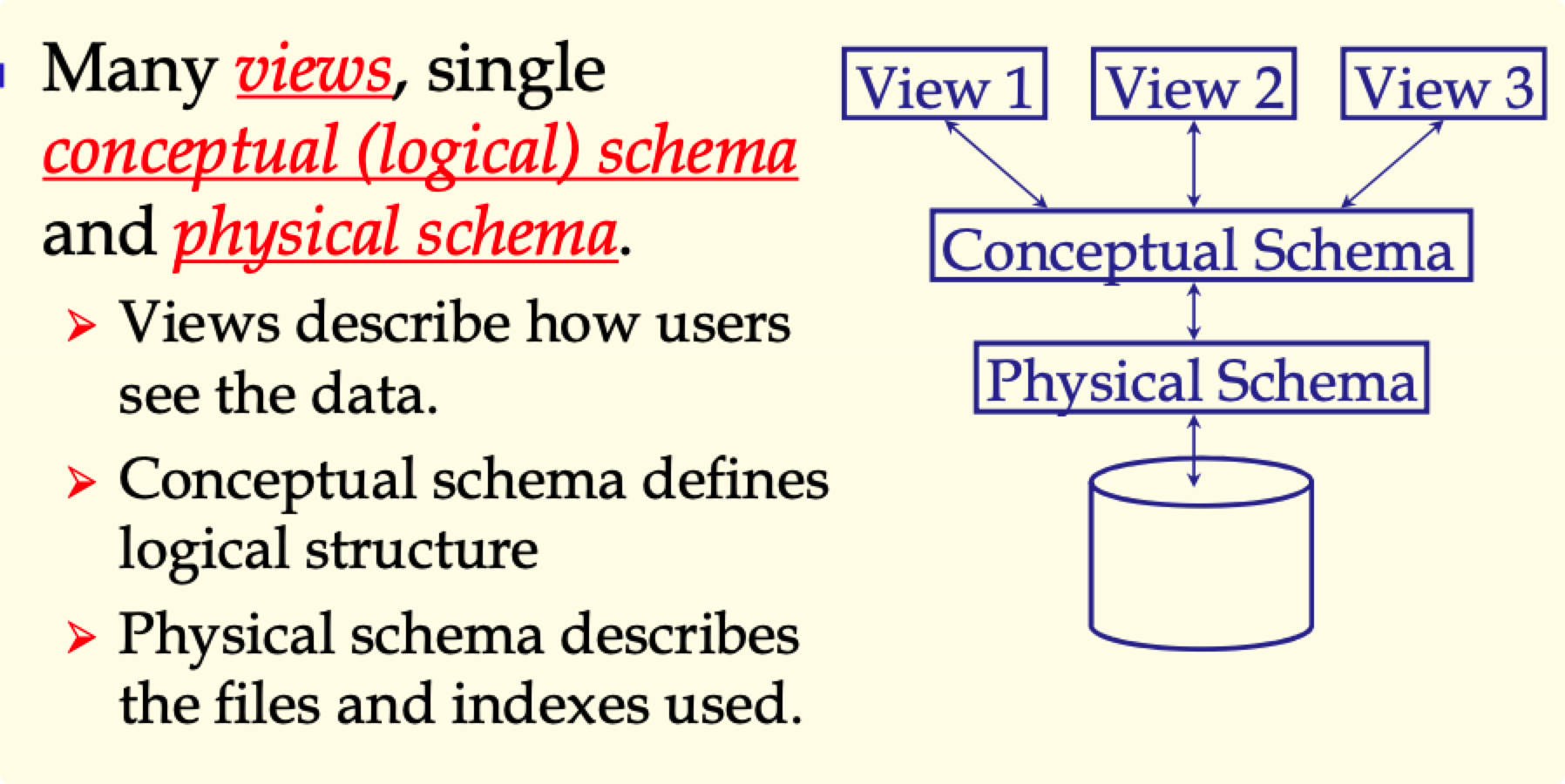
- 应用程序应该独立于数据是如何组织和存储的
- 逻辑独立性:Protection from changes in logical structure of data.
- 物理独立性:Protection from changes in physical structure of data.
数据库系统的组成与生命期 P10
- 组成
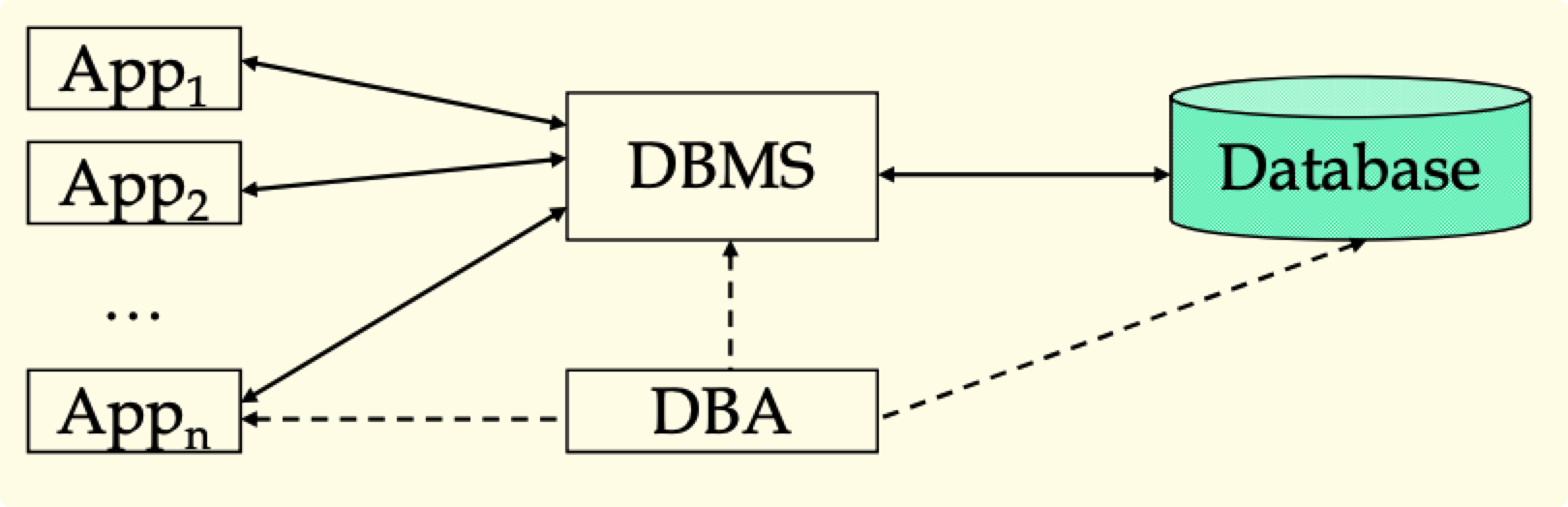
- 生命周期
- 数据库系统规划
- 数据库设计
- 数据库建立
- 数据库运行、管理和维护
- 数据库的扩充和重构
Chapter 2 数据模型
层次数据模型 P12-17
- Basic idea:
- 记录(record)和字段(field)
- Parent-Child relationship
- 虚拟记录
- 大量指针增加数据库开销,数据模式不够清晰、直观
网状数据模型 P17-21
- Basic idea:
- 记录和数据项(data items)
- 系(set)
关系数据模型(重划点)P21-25
基本数据结构:表(或者说是一种关系),可以用严格的数学方法来研究。

- 软连接:

关系
- 相当于一个表(table),包含多个元组
- 关系 R 的 schema:$R=(A_{1}, A_{2},…,A_{n})$,其中 A 是属性名,n 为关系的目(degree)。
键
- 候选键(candidate key)可以由一个或多个属性构成,简称键。
- 至少一个候选键,选择一个作为主键(primarykey),其他候选键为补键(alternate key)
- 超键(super key),至少包含一个键的属性组({学号、出生年月})
- 全键(all key),主键由所有属性构成
- 主属性和非主属性
- 外键(foreign key),一个逻辑指针,指向另一个表中的元组
完整性约束:语意施加在数据上的限制(只有在数据库更新是检查完整性约束)
- 域完整性约束:在域中
- 实体完整性约束:有不为空的主键
- 引用完整性约束:对应外键的元组相等或不存在
- 一般性完整性约束:所有约束
关系代数(Realtional Algebra)P25-29
选择操作(selection):选取某些行
投影操作(projection):选取某些列(产生重复元组)
集合操作(cross-product):并、差、交(要满足并兼容,目、域都相同)
- 笛卡尔乘积(不必并兼容):所有元组各种可能的组合
连接操作(join operation):只连接满足条件的,没有条件的话就是笛卡尔(如不说明,就是自然连接,会消除冗余的等连接)
除操作(division):
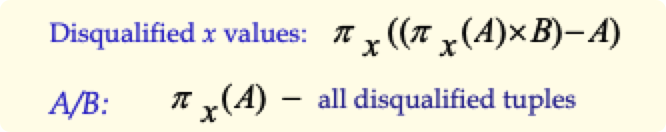
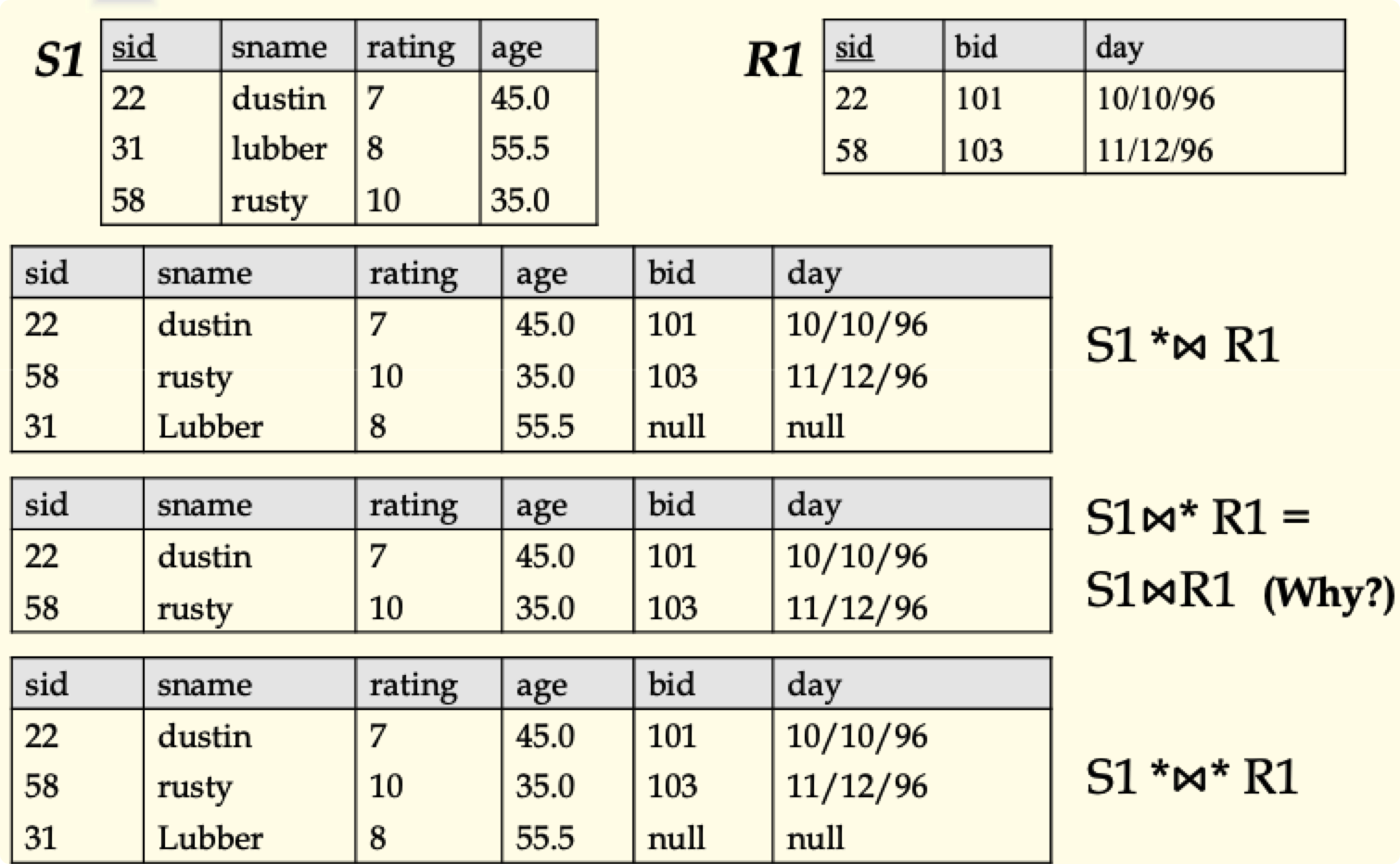
外连接(outer join):左,右,全
- 与连接的区别在于外连接会保留非匹配元组,空缺部分填 NULL
外并(outer union):不用并兼容,无属性的话补 NULL
关系演算(Relational Calculus)P29-30
- 元组关系演算(Tuple Relational Calculus)
- 域关系演算(Domain Relational Calculus)

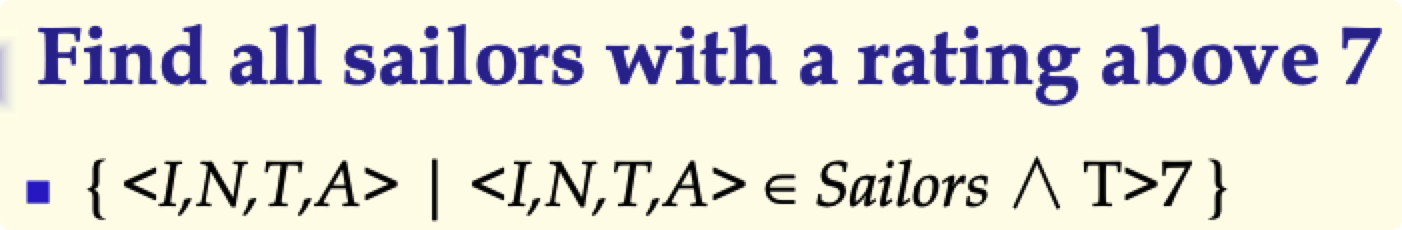
传统数据模型评价 P30-33
- 层次、网状、关系数据模型都是传统数据模型
- 适用于 OLTP(On-Line Transaction Processing)
- 以记录为基础,不能更好的面向用户和应用
- 不能用一种很自然的模式表达实体之间的关系
- 缺少语义信息
- 数据类型少,很难满足应用的需求
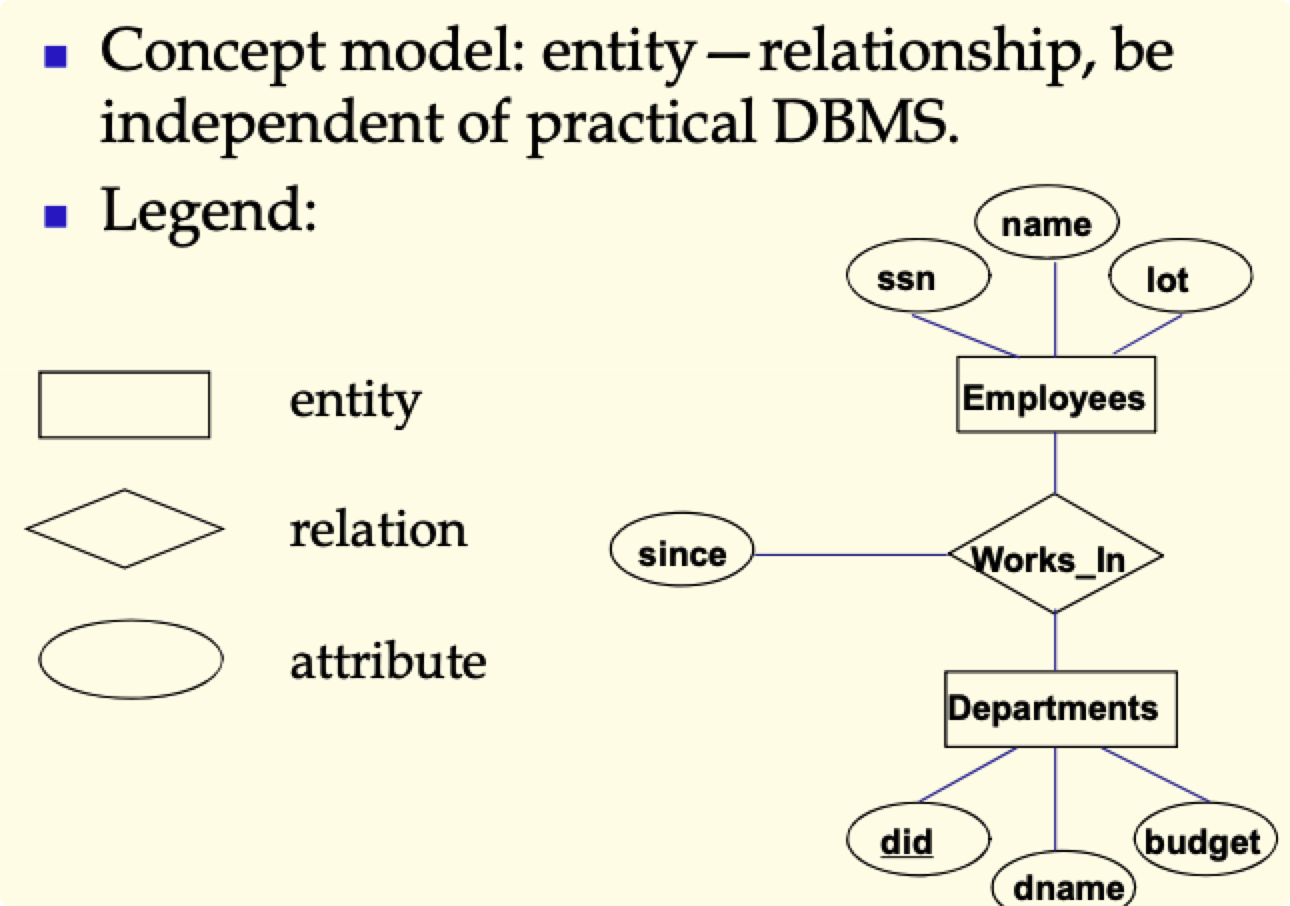
ER 数据模型和面向对象数据模型 P33-44
ER 实体:现实世界中可以和其他物体区分的物体,用一组属性来描述
实体集(Entity Set):相似实体的集合(例子:所有员工)
ER 图 P37-39
- 弱实体(不能单独存在)
- 特殊化和普遍化
- 聚集
- 范畴
(这部分应该不会考很多吧,我就先不看了)
今天又摸了半天鱼,晚安
Chapter 3 数据库语言 SQL
SQL 简介 P56-57
Structured Query Language(or Standard Query Language)
一种非过程语言,用户不需要说明如何获取数据,而只用说需要什么数据
四个功能
- 用来定义、删除或者改变数据模式(Data Definition Language)
- 用来取数据(Query language)
本章重点 - 用来插入、删除或者更新数据(Data Manipulation Language)
本章重点 - 用来控制用户访问数据的权限(Data Control Language)
基本概念
- 基表:数据显示地存在数据库中
- 视图:虚表
查询语言
查询语句基本结构 P62-63
SELECT [DISTINCT] target-list //DISTINCT,消除重复元组
FROM relation-list //关系列表
WHERE qualification //条件执行顺序: FROM WHERE GROUP BY HAVING SELECT ORDER BY(重要!)
简单查询语句 P63-64
后面的例子需要用到的表
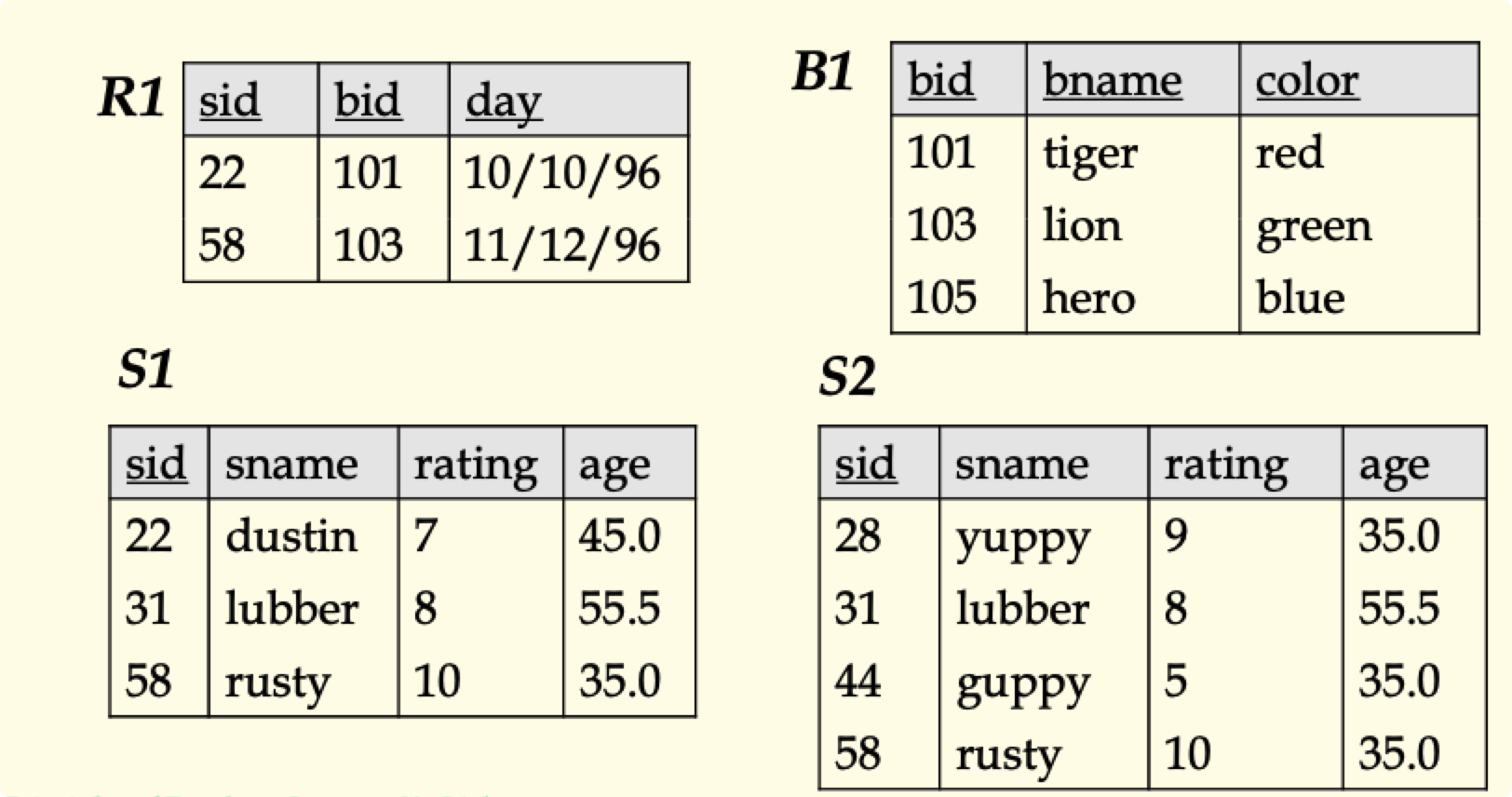
范围变量(Range Variables)
AS- 就是给
FROM后的表取别名
- 就是给
//正常写法
SELECT sname
FROM Sailors, Reserves
WHERE Sailors.sid=Reserves.sid AND bid=103
//取别名
SELECT S.sname
FROM Sailors S, Reserves R
WHERE S.sid=R.sid AND bid=103
- 使用表达式
=ASLIKE
SELECT S.age, age1=S.age-5, 2*S.age AS age2 //AS和’=‘一样,
FROM Sailors S
WHERE S.sname LIKE ‘B_%B’ //'_'表示任意一个字符,'%'表示零个及以上个任意字符基于集合操作的查询语句 P69
用集合的并集和交集
UNION相当于ORUNION ALL表示将所有元组并起来,包括那些重复项,UNION则会去除重复项
//找出预定过红船或绿船的水手 SELECT S.sid FROM Sailors S, Boats B, Reserves R WHERE S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’ UNION SELECT S.sid FROM Sailors S, Boats B, Reserves R WHERE S.sid=R.sid AND R.bid=B.bid AND B.color=‘green’ SELECT S.sid FROM Sailors S,Boats B,Reserves R WHERE S.sid=R.sid AND R.bid=B.bid AND (B.color=‘red’ OR B.color=‘green’)INTERSECT相当于AND
//找出同时预定红船和绿船的水手
SELECT S.sid
FROM Sailors S, Boats B, Reserves R
WHERE S.sid=R.sid AND R.bid=B.bid AND B.color=‘red’
INTERSECT
SELECT S.sid
FROM Sailors S, Boats B, Reserves R
WHERE S.sid=R.sid AND R.bid=B.bidAND B.color=‘green’
SELECT S.sid
FROM Sailors S, Boats B1, Reserves R1, Boats B2, Reserves R2
WHERE S.sid=R1.sid AND R1.bid=B1.bid AND S.sid=R2.sid AND R2.bid=B2.bid AND (B1.color=‘red’ AND
B2.color=‘green’)基于嵌套子查询的查询语句 P66-67
- Nested Queries
- 就是在
FROMWHERESELECT中也可以用 sql 查询INNOT IN
- 就是在
//查找预定过103号船的水手,如果用`NOT IN`就表示没预定过103
SELECT S.sname
FROM SailorsS
WHERE S.sid IN (SELECT R.sid //意思是这个值在选出来的表中
FROM ReservesR
WHERE R.bid=103)
// `(NOT)IN` 也可以用 `(NOT)EXISTS`代替,写法略有不同
SELECT S.sname
FROM Sailors S
WHERE EXISTS (SELECT * //意思应该是存在这样的元组
FROM ReservesR
WHERE R.bid=103 AND S.sid=R.sid)
//如果要查找只预定过一次103这艘船的水手名字呢?
SELECT S.sname
FROM Sailors S
WHERE EXISTS (SELECT *
FROM Reserves R
WHERE R.bid=103 AND S.sid=R.sid)
NOT EXISTS (SELECT *
FROM Reserves R1, Reserves R2)
WHERE ...
AND R1.day != R2.day
//查找只被一个水手预定过的船的bid
SELECT bid
FROM Reserves R1
WHERE bid NOT IN (SELECT bid //被其他水手订过的船的bid
FROM Reserves R2
WHERE R2.sid ¬= R1.sid)op ANYop ALL
//找到一个水手比至少一个叫Horatio的水手评分高的(只要比一个高就行)
SELECT *
FROM SailorsS
WHERE S.rating>ANY (SELECT S2.rating
FROM SailorsS2
WHERE S2.sname=‘Horatio’)除法与聚集函数计算 P66
- Division
//查找那些预定过所有船的水手
SELECT S.sname FROM Sailors S
WHERE NOT EXISTS //不存在没有预定的船
((SELECT B.bid FROM Boats B)
EXCEPT //排除那些已经有人预定过的船的bid
(SELECT R.bid
FROM Reserves R
WHERE R.sid=S.sid))- Aggregate Operators
- COUNTS(*):统计找到的元组总数
- COUNT([DISTINCT] A):返回不重复的属性 A 的值有多少个
- SUM([DISTINCT] A):返回不重复的属性 A 的值总和
- AVG([DISTINCT] A):返回不重复的属性 A 的值平均值
- MAX(A):属性 A 所有值中的最大值
- MIN(A):属性 A 所有值中的最小值
SELECT COUNT (*) //所有的元组
FROM SailorsS
SELECT AVG (S.age) //评分为10的水手平均年龄
FROM SailorsS
WHERE S.rating=10
SELECT COUNT (DISTINCT S.rating) //叫Bob的有多少种评分
FROM SailorsS
WHERE S.sname=‘Bob’
SELECT AVG (DISTINCT S.age) //评分为10的有几种年龄
FROM SailorsS
WHERE S.rating=10
SELECT S.sname //评分最高的水手名字
FROM SailorsS
WHERE S.rating= (SELECT MAX(S2.rating)
FROM SailorsS2)分组聚集函数计算 P68-69
为什么分组
- 例子:要找到每种评分中最年轻的水手(不知道有几种评分)
GROUP BYHAVING通常会和聚集函数一起用- 按列的值分组,一样的分在一组
SELECT [DISTINCT] target-list FROM relation-list WHERE qualification GROUP BY grouping-list HAVING group-qualification //属性必须是grouping-list的子集,不然语法报错- 例子:
//找到年龄大于18的最年轻水手的年纪,并且这个水手的评分必须至少还有一人和他一样 SELECT S.rating, MIN (S.age) AS minage //SELECT最后执行 FROM SailorsS WHERE S.age >= 18 GROUP BY S.rating HAVING COUNT (*) > 1 //HAVING COUNT (*) > 1 AND EVERY (S.age <=60)表示组内水手必须满足所有人年龄小于60 //找到每艘红船的预定数量 SELECT B.bid, COUNT (*) AS scount //3. 再统计每组的数量 FROM Boats B,Reserves R WHERE R.bid=B.bid AND B.color=‘red’ //1. 先找到红船 GROUP BY B.bid //2.然后分组- 聚集函数不能嵌套使用
- 例子
//找到平均年龄最小的评分
SELECT S.rating
FROM Sailors S
WHERE S.age = (SELECT MIN (AVG (S2.age)) //错误!!!
FROM Sailors S2)
//改正
SELECT Temp.rating
FROM (SELECT S.rating, AVG (S.age) AS avgage //2.再取每个组内的平均值
FROM SailorsS
GROUP BY S.rating) AS Temp //1.先按评分分组
WHERE Temp.avgage = (SELECT MIN (Temp.avgage) //3.取平均值值最小的
FROM Temp)fuck 今天是一点不想复习啊
CAST 与 CASE 表达式
CAST
强制数据类型转换
SELECT name, school, CAST(NULL AS Varchar(20))
FROM StudentsCASE
跟在 SELECT 后面
//Officers (name, status, rank, title)
SELECT name, CASE status
WHEN 1 THEN ‘Active Duty’
WHEN 2 THEN ‘Reserve’
WHEN 3 THEN ‘Special Assignment’
WHEN 4 THEN ‘Retired’
ELSE ‘Unknown’
END
AS status
FROM Officers标量子查询
dept(deptno, deptname, location)
emp(deptno, salary, bonus)
- 就是这个子查询只会返回一个元组
//找到那些平均奖金高于平均工资的部门
SELECT d.deptname, d.location
FROM dept AS d
WHERE (SELECT avg(bonus)
FORM emp
WHERE deptno=d.deptno)
> (SELECT avg(salary)
FORM emp
WHERE deptno=d.deptno)表表达式与公共表表达式
- Table Expression
- 就是说会返回一个表
找到那些总支出大于200000的部门们
SELECT deptno, totalpay
FROM (SELECT deptno, sum(salay)+sum(bonus) AS totalpay
FROM emp
GROUP BY deptno) AS payroll WHERE totalpay>200000;- Common Table Expression
- 用
WITH创建一个临时表相当于
- 用
//找到总支出最大的部门
WITH payroll (deptno, totalpay) AS
(SELECT deptno, sum(salary)+sum(bonus)
FROM emp
GROUP BY deptno)
SELECT deptno
FROM payroll
WHERE totalpay = (SELECT max(totalpay)
FROM payroll);
递归子查询
//找到所有上司是Hoover的员工,并且他们的薪水都高于100000
WITH agents (name, salary) AS
((SELECT name, salary --initial query
FROM FedEmp
WHERE manager=‘Hoover’)
UNION ALL
(SELECT f.name, f.salary --recursive query
FROM agents AS a, FedEmp AS f
WHERE f.manager = a.name))
SELECT name --final query
FROM agents
WHERE salary>100000 ;
//一个比较复杂的例子
WITH trips (destination, route, nsegs, totalcost) AS
((SELECT destination, CAST(destination AS varchar(20)), 1, cost
FROM flights --- initial query
WHERE origin=‘SFO’)
UNION ALL
(SELECT f.destination, --- recursive query
CAST(t.route||’,’||f.destination AS varchar(20)),
t.nsegs+1, t.totalcost+f.cost
FROM trips t, flights f
WHERE t.destination=f.origin
AND f.destination<>’SFO’ --- stopping rule 1
AND f.origin<>’JFK’ --- stopping rule 2
AND t.nsegs<=3)) --- stopping rule 3
SELECT route, totalcost --- final query
FROM trips
WHERE destination=‘JFK’ AND totalcost= --- lowest cost rule
(SELECT min(totalcost)
FROM trips
WHERE destination='JFK')
数据操纵语言 P69-71
INSERT
INSERT INTO EMPLOYEES VALUES ('Smith', 'John', '1980-06-10', 'Los Angles', 16, 45000);DELETE
DELETE FROM Person WHERE LastName = 'Rasmussen' ;UPDATE
UPDATE Person SET Address = 'Zhongshan 23', City = 'Nanjing' WHERE LastName = 'Wilson';关于视图 P72-75
普通视图
临时视图和递归查询
嵌入式 SQL P75-79
为了直接在其他编程语言中直接访问数据库
以
EXEC SQL开头,;结尾通过宿主变量(host variables)与程序交流,在 SQL 语句中宿主变量前面必须加
:;只能是一般变量,不能是数组或者其他结构
//定义宿主变量
EXEC SQL BEGIN DECLARE SECTION; char SNO[7];
char GIVENSNO[7];
char CNO[6];
char GIVENCNO[6];
float GRADE;
short GRADEI; /*indicator of GRADE,为负数则表示GRADE为NULL*/
EXEC SQL END DECLARE SECTION;
特殊的宿主变量
SQLCA,通常用SQLCA.SQLCODE来表示 SQL 执行结果<0 表示出错且未执行
=0 表示正常
>0 表示已执行,但有异常
=100 表示无数据可取,通常是数据取完了
CONNECT
EXEC SQL CONNECT :uid IDENTIFIED BY :pwd;- 执行查询或者操作
EXEC SQL INSERT INTO SC(SNO,CNO,GRADE)
VALUES(:SNO, :CNO, :GRADE);
EXEC SQL SELECT GRADE
INTO :GRADE :GRADEI //因为只能查到一个值,所以可以直接赋值
FROM SC
WHERE SNO=:GIVENSNO AND
CNO=:GIVENCNO;CURSOR可以将多个查到的值放入数组
EXEC SQL INCLUDE SQLCA
EXEC SQL BEGIN DECLARE SECTION;
char sname[20];
EXEC SQL END DECLARE SECTION;
EXEC SQL DECLARE student-cursor CURSOR FOR --Step1:声明游标
SELECT S.sname
FROM student S
WHERE S.gpa>3.5
EXEC SQL OPEN student-cursor; --Step2:打开游标
while(TRUE)
{
EXEC SQL FETCH C1 INTO :sname; --Step3: 读数据
if(SQLCA.SQLCODE==100) --读完了
break;
if(SQLCA.SQLCODE<0) --出错了
break;
/*
...处理游标中所取的数据
*/
printf("%s\n", sname);
};
EXEC SQL CLOSE C1; --Step4:关闭游标动态 SQL 与存储过程 P79-82
考到了就现学
Chapter 4 数据库管理系统
DBMS 核心的模块结构 P88-90

- 用户写的应用程序经过接口转为基础的数据库语言(SQL 等)
- SQL 经过词法及语法分析产生语法树
- 之后检查用户是否有权访问语法树涉及的数据对象,若通过则继续执行,否则拒绝执行
- 授权检查通过后,进行语义分析与处理,对四种语言分别做不同处理(通常统称为查询处理),其中 QL 最复杂也最基本,存在多种存取路径选择问题(查询优化) 后就形成 SQL 语句执行
- DLL: 存放 SQL 的动态链接库
- 并发控制: SQL 语句执行过程都有并发控制以防止多用户并发访问数据引起数据不一致
- 恢复机制:发生故障时,能使数据库恢复到最近的一致状态或先前的某个一致状态
- DBMS 是操作系统之上的软件系统,是操作系统的用户,它对系统资源的调用需要请求操作系统为其服务,通过系统调用来实现
事务:DBMS 的执行单位 P89-90
ACID 准则
DBMS 进程结构
单进程结构
- 程进的一单个一是就后行运,起一在接连码代心核 和码代的序程用应把
多进程结构
- 一个应用对应一个 DBMS 进程
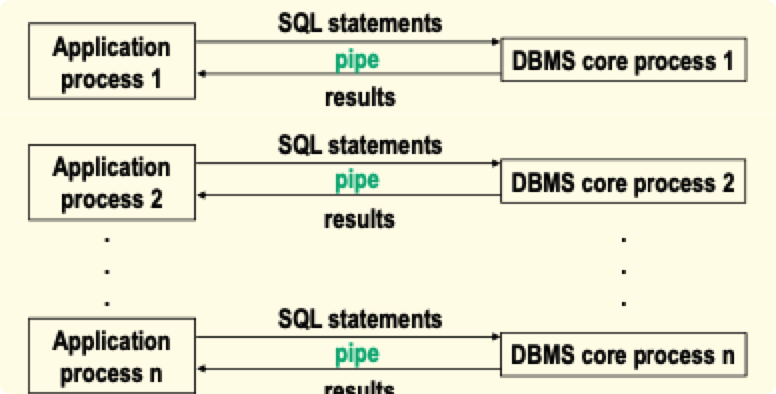
- 一个应用对应一个 DBMS 的一个线程
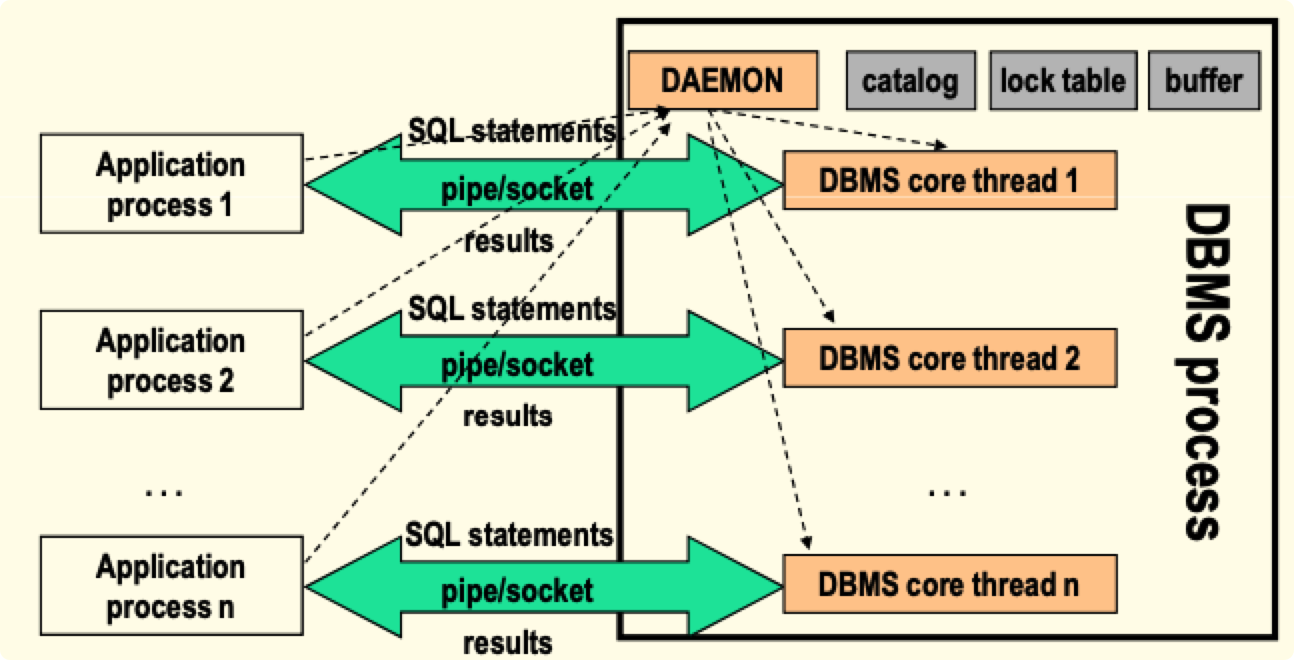
数据库访问管理 P101-111
- 访问类型
- 查询一个文件的全部或大部分记录(>15%)
- 查询某一条特定记录
- 查询某些记录(<15%)
- 范围查询
- 记录的更新
- 文件管理
- 堆文件
- 记录按插入顺序存放,就像堆货物一样。物理地址不一定连续,逻辑地址连续。插入容易,查找难,只能顺序搜索,删除麻烦,一般不在物理上删除,只是打删除标志,以免引起大量记录转移。
- 直接文件
- 将记录某一属性(一般为主键)用散列函数映射成记录的地址。按散列键访问快,但不同散列键可能映射同一地址,且只对散列键到记录的访问有效,键映射空间固定,不变处理变长记录,用得少
- 索引文件
- 索引+堆文件/簇集
- 在记录的某一属性(组)上建立索引,索引项由索引键的值及其对应的记录的地址货地址集组成。
- 提高查询效率,增加索引维护开销,付出储存空间代价
- 堆文件
- 索引
- B+树(最常用)
- Clustering index(常用)
- 倒排文件
- 动态 hash
- 栅格结构文件
查询优化
代数优化(粗糙的优化)
- 对查询进行等效变化,以减少执行的开销
- 先一元操作,后二元操作,可以提取一些公共操作
操作优化(优化的重点)
合理选择存取路径
选择、投影、集合、连接、组合操作的优化
主要是连接操作的优化,因为开销最大
嵌套循环法
- R 为外关系,共 bRb_Rb\*R条记录,S 为内关系,共 bSb_Sb**S条记录,R 每次 I/O 取出的为缓冲块大小的元组个数,设有 nBn_Bn**B*个缓冲块,一块用于内关系缓冲,其余用于外关系缓冲,则共需访问物理块数,从公式可以看出要想减少 I/O 次数,应该让小关系作为内关系,因为它前面有个乘数。
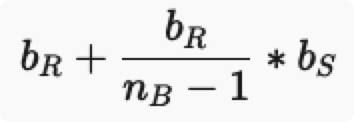
- 为什么缓存块都给外缓冲?
- 因为,内关系的扫描次数取决于外关系分多少次取完,外关系每次取的越多,则内关系一次扫描所比较的元组也越多。而内关系每次扫描都要 I/O 整个表,而总的 I/O 次数中外关系的 I/O 次数是定值(它只用扫描一次),内关系的 I/O 次数只取决于其扫描次数 ↣\rightarrowtail↣ 其扫描次数只取决于外关系取的次数 ↣\rightarrowtail↣ 外关系取的次数取决于每次取多少,所以增大外缓冲能有效减小内关系扫描次数。
利用索引或散列寻找匹配元组法
排序归并法
散列连接法
恢复机制
减少可能出现的错误
从错误中恢复
周期性转储
每隔一段时间将磁盘数据转储到磁带(不受系统故障影响)上
转储采用增量转储
只能恢复到最近一次备份
备份+日志
- 日志(Log):记录上次备份以来所有数据库的改变
- 前像(Before Image)
- 事务更新时所涉及物理块更新前的映像;有前像可使数据库回到更新前状态,即撤销更新 undo,满足幂等性,就是无论 undo 几次都和 undo 一次的效果一样
- 后像(A.I)
- 事务更新时所涉及物理块更新后的映像;有后像即时更新数据丢失,仍可恢复到更新后状态,叫重做 redo,也满足幂等性
- 事务状态:两种,commit 了,说明事务已成功执行(all);事务失败,则要消除事务对数据库影响(nothing),叫卷回(abort/rollback) 数据库失效时,可取出最近副本,再根据运行记录
- 对已提交的事务用后像重做,叫向前恢复
- 对未提交的事务用前像卷回,叫向后恢复 这样可使数据库恢复至最近的一致状态
- 前像(Before Image)
- 日志(Log):记录上次备份以来所有数据库的改变
数据结构
- Commit list :所有已经提交的事物列表
- Active list:当前在运行的、还没有提交的事物的标识符(TID)
- Log
提交规则
- A.I 必须在 commit 之前就写入硬盘
日志提前规则
- 若 A.I 在事务提交之前写入数据库,必须先把 B.I 先写入 Log
幂等性
- redo 和 undo 做几次都效果一样
三种更新策略
A.I 在事务提交之前写入 DB:
- TID 写入 active list
- B.I 写入日志[Log Ahead Rule]
- A.I 写入 DB [Commit Rule]
- TID 写入 commit list
- 在 active list 中删去 TID

A.I 在事务提交之后写入 DB: (流行的用法)
TID 进入 active list
A.I 写入 log[Commit Rule]
TID 写入 commit list
A.I 写入 DB
在 active list 中删去 TID
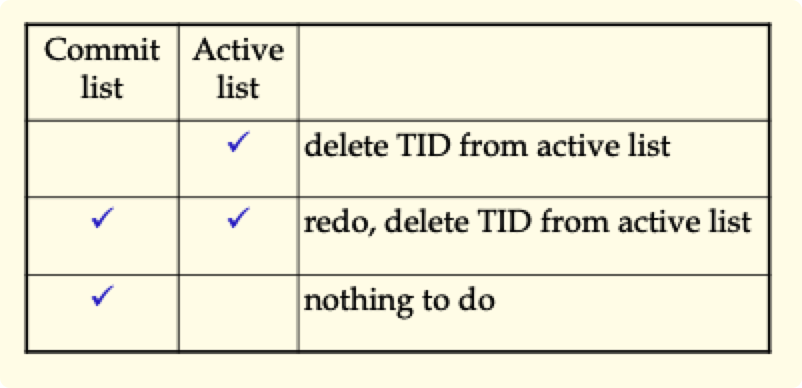
A.I 写入 DB 与 commit 并发进行:
TID 进入 active list
A.I 和 B.I 写入 log[Two Rules]
A.I 写入 DB(partially done)
TID 写入 commit list
A.I 写入 DB(completed)
在 active list 中删去 TID

并发控制 P148-153
并发的问题
- 丢失更新(write-write conflict)
- 读脏数据(read-write conflict)
- 读值不可复现
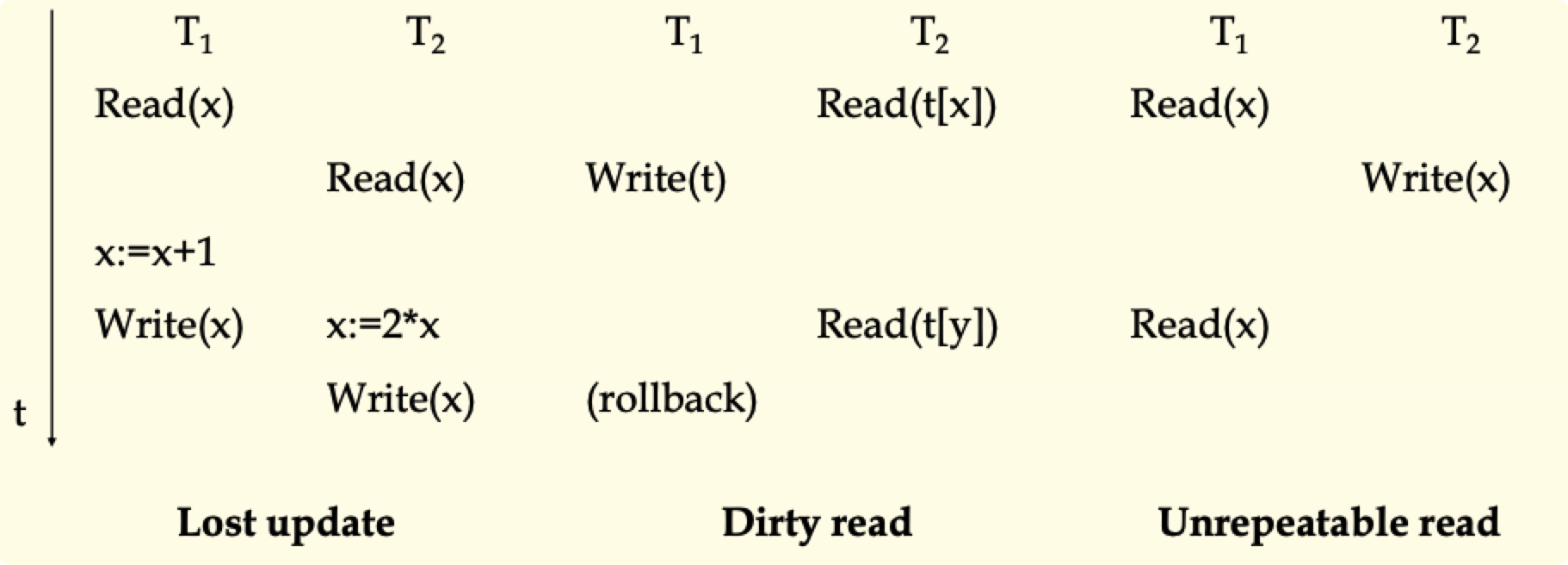
加锁协议
2PL(two phase locking): 释放锁在所有加锁之后
well-formed:遵循先加锁,后操作
X 锁(排他性)
\ NL X NL Y Y X Y N (S,X)锁,S 用于读,X 用于写
\ NL s x NL Y Y Y S Y Y N X Y N N (S,U,X 锁),S 用于读,U 锁一般先申请,然后去更新数据,在最后写入阶段再去申请 X 锁,X 用于写
\ NL S u x NL Y Y Y Y S Y N Y N U Y Y N N X Y N N N
死锁与活锁 P156-159
死锁:循环等待,没有事务可以得到需要的资源来完成事务
处理:预防&解决
检测死锁:
- 超时法:超过某一时限,则认为发生死锁
- 等待图法:出现回路则有死锁
防止死锁
- 与操作系统类似的方法
- 将数据对象按序编号,按序申请
- 当事务申请锁未获准时不是一律等待,而是让一些事务卷回重执(retry),以避免循环等待。为区别事务开始执行的先后,给他们一个随时间增长的时间标记 ts(time stamp)
- 事务重执有两种策略
- 死亡-等待 wait-die:年老的等年轻的事务,年轻的来了,则重执,一直到自己变得年老而等待
- 击伤-等待 wound-die:年轻的等年老的,年老的来了,把年轻的击败,年轻的重执时直接等待
- 事务重执有两种策略
活锁:别的事务一直占用资源,低优先级的一直拿不到资源
- 处理:FIFO
Chapter 5 数据库的安全与完整性约束
数据库的安全
- 利用视图和查询修改
- 访问控制(对用户进行分类来给不同的权限 )
- 普通用户
- DBA
- 有资源特权的用户
- 用户标识和用户认证
- 通过 password 进行用户认证
- 特殊的物品,如钥匙. IC 卡等等
- 授权
- Role 角色机制(通过该方法提高权限控制)
- 数据加密
- 加密后存储【密码学】,但是加密解密影响效率
- 审计追踪
- 结合数据库日志,可以在关注的对象上添加审计追踪,会记录该对象上进行的操作
完整性约束
完整性约束就是规则,一张表内所有元组都要满足的条件就是完整性约束
完整性约束的分类
静态约束
- 固有约束:数据模型固有的约束,如关系属性应该是原子的,即第一范式
- 隐含约束:数据库表的模式定义里面的约束,一般用 DDL 语句说明,如:域约束、实体完整性约束、外键约束【引用完整性约束】
- 显式约束:书 p181,没解释清
动态约束
- 数据库在状态转换中要满足的约束叫做动态约束(可以和触发器联系)
完整性约束的说明
用过程说明:把约束的说明和检验交给应用程序
用断言说明:断言指数据库状态必须满足的逻辑条件
在基表定义中加入
CHECK子句约束用触发子表示约束,下小节细讲
CREATE TABLE Sailors(
sid INTEGER,
sname CHAR(10),
rating INTEGER,
age REAL,
PRIMARY KEY(sid),
CHECK(rating>=1 AND rating<=10));
CREATE TABLE Sailors (
sid INTEGER,
sname CHAR(10),
age REAL,
PRIMARY KEY(sid),
CHECK(
(SELECT COUNT(S.sid) FROM Sailors S)
+(SELECT COUNT(B.bid) FROM Boats B)<100)触发器
- 主动数据库:能对数据库采取一些主动的动作。
- 数据库的主动依赖于规则
- 规则:ECA 规则,E 为事件、C 为条件、A 为动作。
- 即当事件 E 发生,且条件 C 满足时,采取 A 动作
- 数据库的主动依赖于规则
//在往水手表中插入水手时,若年龄小于18则插入年轻水手表
CREATE TRIGGER youngSailorUpdate --声明触发器
AFTER INSERT ON SALORS --Event
REFERENCING NEW TABLE NewSailors --对水手表新插入的元组看成一张表
FOR EACH STATEMENT --触发行为
INSERT
INTO YoungSailor(sid, name, age, rating)
SELECT sid, name, age, rating
FROM NewSailors N
WHERE N.age <=18触发器的执行策略
立即执行【常用】
- 当事件发生时立刻去检查条件是否满足
延迟执行
- 等事务要提交时执行
分离执行
- 把 ECA 规则中的动作单独作为一个事务,作为原来事务的衍生事务
Chapter 6 数据库设计
数据依赖
函数依赖 FD
- 一个属性的值可以决定其他属性的值
多值依赖 MVD
- 一个属性的值可以决定其他一组值
连接依赖 JD
- the constraint of lossless join decomposition.
关系模式的规范化
1NF 一范式
- 关系的属性必须是原子的(意思应该就不能是对象或数组这种)
2NF 二范式
3NF 三范式
- 满足二范式
- 不存在属性对主键的传递依赖
- 例子 :若属性由(职工编号、工资级别、工资)三个属性组成,其中(职工编号)为主键。
- 分析:工资取决于工资级别,取决于职工编号
- 上例不满足 3 范式的问题
- 插入异常:当一个人的工资级别还没定的时候,他对应的工资也没有
- 删除异常:若只是删除一个员工的工资信息时,会把对应的工资级别信息也删除了
- 更新异常:数据内有大量的冗余
- 解决方法
- 设计时,一视一地。
- 一张表只管一件事情
- 设计时,一视一地。
4NF 四范式
- 在满足三范式的前提下,消除多值依赖。
5NF 五范式
在满足四范式的前提下,消除连接依赖。
## 数据库设计方法
面向过程的方法
- 根据单位日常处理的流程,以过程为中心。
- 好处
- 在设计初期,能比较快的实现
- 缺点
- 没分析数据之间的关系,数据由冗余和矛盾,当流程进行改动时,会有很多问题
- 好处
- 根据单位日常处理的流程,以过程为中心。
面向对象的方法
需求分析
- 数据字典
- 把所有的基本数据元素都找出来
- 解决问题:
- 名字冲突:同名异意
- 概念冲突
- 域冲突
- 编码问题
- 压缩信息
- 基本信息
- 实体识别
- 解决问题:
- 把所有的基本数据元素都找出来
- 数据字典
概念设计
- 用 ER 图抽象出实体
- 哪些数据项抽象成实体
- 实体间的联系
- 相关 ER 图工具
逻辑设计
- 把 ER 图表达的数据模型进行建表
- 表和属性的命名规则
- 逆规范化
- 定义视图
- 考虑遗留系统的表的设计
物理设计
- 根据 DBMS 特点对每个表的存储和索引情况进行权衡
- 分区设计
总结
- 仅仅在结构上满足 3 范式是不够的
- 一事一地包括每项信息的唯一,要提取出问题的本质,识别本质上同一概念的信息项
- 对于表达类似信息、能合并尽量合并
- 考虑到效率、用途等因素、该分开的要分开
- 结合 DBMS 内部实现技术,合理设计索引和文件结构,为查询优化准备号存取路径
- 在结构规范化、减少数据冗余和提高数据库访问性能之间仔细权衡,适当折中
(勉强整理完了)

